Collections - Map interface
- Map Interface
- Hashing
- Buckets for nodes and indexes for the buckets
- Nodes
- Index Calculation in Hashmap
- Internal workings of a Hashmap
- Hashmap vs Hashtable
- Linked HashMap Class
- What Are the different Collection Views That Maps Provide?
- KeySet View
- Values Collection View
- EntrySet View
- Sorted Map interface
- How to Iterate HashMap in Java?
- Sorting a Map
Map Interface
A Map is an object that maps keys to values. A map cannot contain duplicate keys: Each key can map to at most one value. It models the mathematical function abstraction.
- A map is an object that stores associations between keys and values (key/value pairs).
- Given a key, you can find its value. Both keys and values are objects.
- The keys must be unique, but the values may be duplicated.
- Some maps can accept a null key and null values, others cannot.
The main implementations of the Map interface are as follows:
- HashMap
- HashTable - How does a Hashtable internally maintain the key-value pairs?
- TreeMap - TreeMap actually implements the SortedMap interface which extends the Map interface. In a TreeMap the data will be sorted in ascending order of keys according to the natural order for the key’s class, or by the comparator provided at creation time. TreeMap is based on the Red-Black tree data structure.
- EnumMap
HashMap vs TreeMap
| Operations | HashMap | TreeMap |
|---|---|---|
| Insert key-value pair | amort. O(1), worst O(n) | O(log n) |
| Look up the value associated with a given key | O(1) | O(log n) |
- For inserting, deleting, and locating elements in a Map, the HashMap offers the best choice.
- However, if you need to traverse the keys in a sorted order, then TreeMap is your better alternative.
- Depending upon the size of your collection, it may be faster to add elements to a HashMap, than convert the map to a TreeMap for sorted key traversal.
HashMap vs ConcurrentHashMap
- HashMap is non-Synchronized in nature i.e. HashMap is not Thread-safe whereas ConcurrentHashMap is Thread-safe in nature.
- HashMap performance is relatively high because it is non-synchronized in nature and any number of threads can perform simultaneously. But ConcurrentHashMap performance is low sometimes because sometimes Threads are required to wait on ConcurrentHashMap.
- While one thread is Iterating the HashMap object, if other thread try to add/modify the contents of Object then we will get Run-time exception saying ConcurrentModificationException.Whereas In ConcurrentHashMap we wont get any exception while performing any modification at the time of Iteration.
References:
- https://www.geeksforgeeks.org/java/difference-hashmap-concurrenthashmap/
- https://javaconceptoftheday.com/hashmap-vs-concurrenthashmap-in-java/
LinkedHashMap
- Maintains insertion order, but doesn’t sort by keys.
TreeMap class
- Specifically designed for sorting keys, providing a natural or custom sorting order.
- Custom Comparator: You can use a Comparator with TreeMap or Stream.sorted() to define specific sorting rules if needed.
- A Red-Black tree based NavigableMap implementation.
- The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used.
- This implementation provides guaranteed log(n) time cost for the containsKey, get, put and remove operations.
HashMap class
https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
https://en.wikipedia.org/wiki/Hash_table
A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
Ideally, the hash function will assign each key to a unique bucket, but most hash table designs employ an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. Such collisions are typically accommodated in some way.
In a well-dimensioned hash table, the average time complexity for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key–value pairs, at amortized constant average cost per operation.
Hashing is an example of a space-time tradeoff. If memory is infinite, the entire key can be used directly as an index to locate its value with a single memory access. On the other hand, if infinite time is available, values can be stored without regard for their keys, and a binary search or linear search can be used to retrieve the element.
In many situations, hash tables turn out to be on average more efficient than search trees or any other table lookup structure. For this reason, they are widely used in many kinds of computer software, particularly for associative arrays, database indexing, caches, and sets.
https://www.geeksforgeeks.org/java-util-hashmap-in-java-with-examples/
Hashing
Hashing is a process of converting an object into integer form by using a hash function - in Java, it is done by the hashCode() method.
hashCode() method
hashCode()method is used to get the hash code of an object.- By default,
hashCode()method of the object class returns the memory reference of an object in integer form. However, it is possible to provide your implementation ofhashCode(). - Definition of
hashCode()method ispublic native hashCode(). - It indicates that the implementation of
hashCode()is native because there is not any direct method in java to fetch the reference of the object.
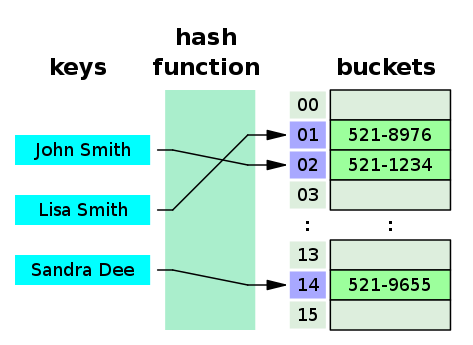
Buckets for nodes and indexes for the buckets
- A bucket is one element of the HashMap array.
- Buckets are used to store Nodes.
- Multiple Nodes can be put in the same bucket. This is done in scenarios where the hash function generates the same index for more than one key (Hash collisions).
- A linked list structure is one way to connect the Nodes in scenarios where there is a hash collision.
- Buckets are different in capacity.
- A relation between bucket and capacity is as follows:
capacity = number of buckets * load factor - A single bucket can have more than one Node. How the Nodes are placed in buckets depends on the hashCode() method. The better your hashCode() method is, the better your buckets will be utilized.
- In the example below, 01, 02 and 14 are the indexes for buckets.
Nodes
Internally, buckets contains an array of Nodes. A Node is represented as a class that contains 4 fields:
┌─────────────────┐
│ Node<K,V> │
├─────────────────┤
│ int hash │
│ K key │
│ V value │
│ Node<K,V> next │
└─────────────────┘
Index Calculation in Hashmap
A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found.
Ideally, the hash function will assign each key to a unique bucket, but most hash table designs employ an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. Such collisions are typically accommodated in some way.
In a well-dimensioned hash table, the average time complexity for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key–value pairs, at amortized constant average cost per operation.
Time complexity is almost constant for the put() and the get() methods until rehashing is not done.
Hashing is an example of a space-time tradeoff. If memory is infinite, the entire key can be used directly as an index to locate its value with a single memory access. On the other hand, if infinite time is available, values can be stored without regard for their keys, and a binary search or linear search can be used to retrieve the element.
Internal workings of a Hashmap
How does the put() method of HashMap work
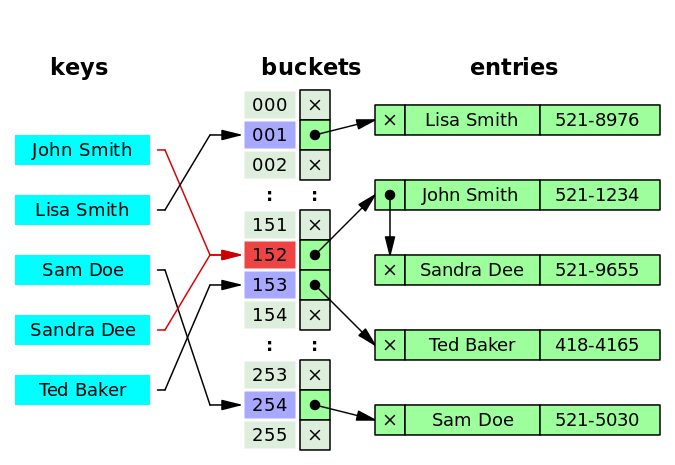
Putting the first object in the HashMap:
map.put(new Key("John Smith"), 521-1234);
Steps:
- Calculate hash code of Key {“John Smith”}. e.g. hashcode = JohnSmithHashCode-fyujykkuio
- Calculate index for this hashcode by using index method. e.g. index = 152
- Create a node object:
{ int hash = JohnSmithHashCode-fyujykkuio Key key = {"John Smith"} // {"John Smith"} is not a string but an object of class Key. String value = "521-1234" Node next = null } - Place this Node at index 152, if no other Node exists at that index.
Putting a second object in the HashMap:
map.put(new Key("Sam Doe"), 521-5030);
Steps:
- Calculate hash code of Key {“Sam Doe”}. e.g. hashcode = SamDoeHashCode-hjkkulu
- Calculate index for this hashcode by using index method. e.g. index = 254
- Create a node object:
{ int hash = SamDoeHashCode-hjkkulu Key key = {"Sam Doe"} String value = "521-5030" Node next = null } - Place this Node at index 254, if no other Node exists at that index.
Putting a third object in the HashMap:
map.put(new Key("Sandra Dee"), 521-9655);
Steps:
- Calculate hash code of Key {“Sandra Dee”}. e.g. hashcode = SandraDeeHashCode_67jhkkl
- Calculate index for this hashcode by using index method. e.g. index = 152
- Create a node object:
{ int hash = SandraDeeHashCode-67jhkkl Key key = {"Sandra Dee"} String value = "521-9655" Node next = null } - Place this object at index 152.
- But there was already a Node at index 152 - this is a case of collision.
- Check via the hashCode() and equals() methods if both the keys are the same.
- If the keys are the same, replace the previous Node with the current Node.
- If the keys are the different, create a new Node and connect this new Node to the previous Node that was already in the bucket with index = 152.
In the example below, the objects with keys “John Smith” and “Sandra Dee” have the same index. This means that both of these objects are put in the same bucket.
How does the get() method of HashMap work
- When we pass an object to
put()method to store it on hashMap, hashMap implementation callshashcode()method on the key object and by applying that hashcode on its own hashing funtion it identifies an index for a bucket location for storing the object as a Node. - The steps for the
get()operation are the opposite of the steps that were used in theput()method. - The important part here is HashMap stores both key and value as part of each Node (in a linked list) in the buckets. This is essential to understand the retrieving logic.
- If you fail to recognize this and imagine that only the Values are stored in the buckets, you will fail to explain the retrieving logic of any object stored in HashMap.
- While retrieving it uses key object equals method to find out correct key value pair and return value object associated with that key. HashMap uses linked list in case of collision and object will be stored in next node of linked list.
Lets run through a scenario:
Fetch the data for key Sam Doe
map.get(new Key("Sam Doe"));
Steps:
- Calculate hash code of Key {“Sam Doe”}. e.g. hashcode = SamDoeHashCode-hjkkulu.
- Calculate index for this key. e.g. index = 254.
- Go to index 254 of the array of buckets and compare the first Node’s key with the given key. If both are equal, then return the value, otherwise, check for the next Node if it exists.
- In our case, it is found as the first Node and the returned value is 521-5030.
Fetch the data for key Sandra Dee:
map.get(new Key("Sandra Dee"));
Steps:
- Calculate hash code of Key {“Sandra Dee”}. e.g. hashCode = SandraDeeHashCode-67jhkkl.
- Calculate index. e.g. index = 152.
- Go to index 152 of the array of buckets. Compare the first Node’s key with the given key. If both are equal, then return the value of the Node. Otherwise, check for the next Node if it exists.
- In our case, it is not found as the first Node and the next Node object is not null.
- If the next node is null, then return null.
- If the next of Node is not null, traverse to the second element and repeat process 3 until the key is not found or next is not null.
- In case of collision, i.e. index of two or more Nodes are the same, Nodes are joined by a linked list i.e. the second Node is referenced by the first Node and the third by the second, and so on.
- When getting an object with its key, the linked list is traversed until the key matches or null is found on the next field.
Collision Detection and Collision Resolution in Java HashMap
- As we have seen in the details to put an object into a HashMap, the first part is computing a hash function which transforms the search key into an array index.
- The ideal case is such that no two search keys hashes to the same array index.
- However, this is not always the case and is impossible to guarantee for unseen given data.
The two common methods for collision resolution are separate chaining and open addressing.
https://en.wikipedia.org/wiki/Hash_table#Separate_chaining
https://en.wikipedia.org/wiki/Hash_table#Open_addressing
Resizing of hashmap in Java
(Multiple thread accessing the java hashmap and potentially looking for race condition on HashMap in Java.) There is potential race condition while resizing hashmap in Java. If two threads found that now Java Hashmap needs resizing and they both try to resize at the same time. In the process of resizing of hashmap in Java, the elements that are stored in the bucket in the linked list get reversed in order during their migration to new bucket because java hashmap doesn’t append the new element at tail instead it append new element at head to avoid tail traversing. If there is a race condition, then you will end up with an infinite loop.
Hashmap vs Hashtable
https://www.geeksforgeeks.org/differences-between-hashmap-and-hashtable-in-java/
- HashMap is non-synchronized. It is not thread-safe and can’t be shared between many threads without proper synchronization code whereas Hashtable is synchronized. It is thread-safe and can be shared with many threads.
- HashMap allows one null key and multiple null values whereas Hashtable doesn’t allow any null key or value.
- HashMap is generally preferred over HashTable if thread synchronization is not needed.
- The HashMap class is roughly equivalent to Hashtable, except that it is non synchronized and permits nulls. (HashMap allows null values as key and value whereas Hashtable doesn’t allow nulls).
- HashMap does not guarantee that the order of the map will remain constant over time.
- HashMap is non synchronized whereas Hashtable is synchronized.
- Iterator in the HashMap is fail-fast while the enumerator for the Hashtable is not and throw ConcurrentModificationException if any other Thread modifies the map structurally by adding or removing any element except Iterator’s own remove() method. But this is not a guaranteed behavior and will be done by JVM on best effort.
Why does HashTable not allow null and HashMap do?
In order to successfully store and retrieve objects from a HashTable, the objects used as keys must implement the hashCode method and the equals method. Since null is not an object, it can’t implement these methods. HashMap is an advanced version and improvement on the Hashtable. HashMap was created later.
| Hashmap | Hashtable |
|---|---|
| No method is synchronized. | Every method is synchronized. |
| Multiple threads can operate simultaneously and hence hashmap’s object is not thread-safe. | At a time only one thread is allowed to operate the Hashtable’s object. Hence it is thread-safe. |
| Threads are not required to wait and hence relatively performance is high. | It increases the waiting time of the thread and hence performance is low. |
| Null is allowed for both key and value. | Null is not allowed for both key and value. Otherwise, we will get a null pointer exception. |
| It is introduced in the 1.2 version. | It is introduced in the 1.0 version. |
| It is non-legacy. | It is a legacy. |
Linked HashMap Class
Hash table and linked list implementation of the Map interface, with predictable iteration order. This implementation differs from HashMap in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order).
What Are the different Collection Views That Maps Provide?
Maps Provide Three Collection Views.
- Key Set - allow a map’s contents to be viewed as a set of keys.
- Values Collection - allow a map’s contents to be viewed as a set of values.
- Entry Set - allow a map’s contents to be viewed as a set of key-value mappings.
KeySet View
KeySet is a set returned by the keySet() method of the Map Interface, It is a set that contains all the keys present in the Map.
Values Collection View
Values Collection View is a collection returned by the values() method of the Map Interface, It contains all the objects present as values in the map.
EntrySet View
Entry Set view is a set that is returned by the entrySet() method in the map and contains Objects of type Map. Entry each of which has both Key and Value.
Sorted Map interface
A Map that further provides a total ordering on its keys. The map is ordered according to the natural ordering of its keys, or by a Comparator typically provided at sorted map creation time. This order is reflected when iterating over the sorted map’s collection views (returned by the entrySet, keySet and values methods). Several additional operations are provided to take advantage of the ordering. (This interface is the map analogue of SortedSet.)
How to Iterate HashMap in Java?
Sorting a Map
- Just use a TreeMap
- https://www.baeldung.com/java-hashmap-sort