Zookeeper - Watchers, Triggers and Failure Detection
- Purpose
- Watchers
- What to do when the application receives an event notification from Zookeeper server
- Using Watchers for Failure Detection
- Leader Re-election Algorithm
- The Herd effect
- Leader Re-election Algorithm that eliminates The Herd Effect
- Internal references
- Fault Tolerance and Horizontal Scalability
- Zookeeper client API is asynchronous and event driven.
Purpose
Implement failure detection with Zookeeper
Watchers
- To get notified about events, such as a successful connection or disconnection, we need to register an event handler and pass it to the Zookeeper as a Watcher object.
- We can register a watcher when we call these methods. In other words, Zookeeper allows us to pass a reference to a Watcher object when we call these methods.
- getChildren()
- getData()
- exists()
- A Watcher is an object to register with Zookeeper so that the application will get a notification event when a change happens on the Zookeeper server.
- e.g. If we make this call
getChildren(.., watcher), the application will be notified when the list of a znode’s children changes. - e.g. If we make this call
exists(znodePath, watcher), the application will be notified if a znode gets deleted or created - e.g. If we make this call
getData(znodePath, watcher), the application will be notified if a znode’s data gets modified - Establishing connection also takes a Watcher
Watcher watcher; new ZooKeeper(ZOOKEEPER_ADDRESS, SESSION_TIMEOUT, watcher); - To be a Watcher, a class needs to implement the
Watcher interfaceand theprocess()method. - This
process()method will be called by the Zookeeper library on a separate thread whenever there is a new event coming from the Zookeeper server. - Watchers registered with
getChildren(),exists()andgetData()are one-time triggers - meaning, we get notified only once when a change happens. If we want to get notified for future similar events, we need to register the watcher again.
What to do when the application receives an event notification from Zookeeper server
Handle the event based on the type of the event
- When we get a new event, we need to figure out what type of event it is.
- Generally, zookeeper connection events don’t have any type.
- So when we get an event of type
None, we check the zookeeper state.
Using Watchers for Failure Detection
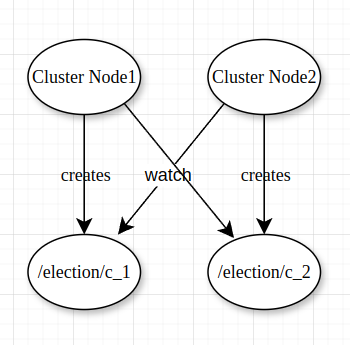
The cluster nodes creates Ephemeral znodes with the Zookeeper server.
Cluster Node1 calls exists() on znode2 and registers a watcher.
Cluster Node2 calls exists() on znode1 and registers a watcher.
Now, if Cluster Node1 disconnects or dies, it’s ephemeral znode (znode1) will be deleted by the Zookeeper. So, a notification/event will be received by Cluster Node2 because it registered a watcher. Cluster Node2 will know that znode1 is deleted. Now, Node2 will know that Node1 is down.
This way, we can know (and take action) if another Node in the cluster disconnects/fails/dies.
Leader Re-election Algorithm
Applying the “Watchers Failure Detection” approach to leader election algorithm
Step1:
We brought some Cluster Nodes up in our cluster. By this point, the leader election is completed. One of them is the leader and the rest of them are not the leader.
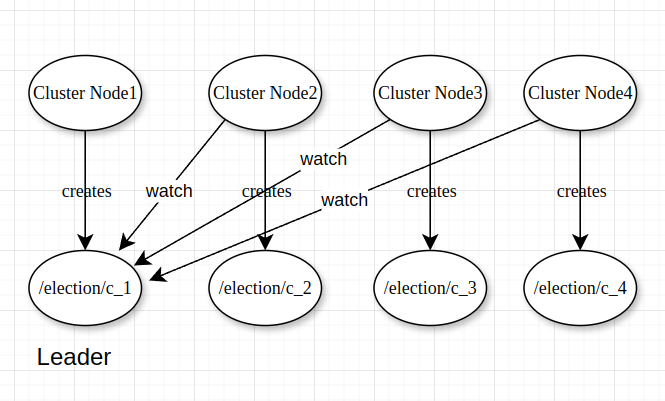
If the Leader dies and it’s ephemeral node gets deleted, then all the other Nodes in the cluster get notified. They can start the re-election of a new leader.
The Herd effect
- A large number of Nodes are waiting for an event (e.g. a leader dying)
- When that event occurs, then all the other Nodes get notified and they all try to act on it.
- Even though all the rest of the Nodes in the cluster try to take an action, only one of them can “succeed” (e.g. become a leader)
- This type of a design is bad. It can negatively impact the performance or even completely freeze the cluster.
- With the previous design, if the leader dies, the Zookeeper has to notify a potentially large cluster of Nodes about that event. Then, all the Nodes will call the
getChildren()to get a new view of the znodes hierarchy. All the Nodes will bombard Zookeeper with requests at the same time. Again, after a new leader is re-elected, all the Nodes will keep watching the znode of the leader - which, in turn, will send a lot of requests to Zookeeper simultaneously. - With a large number of Nodes in the cluster, this can overwhelm Zookeeper. We should avoid this type of design as much as possible.
Leader Re-election Algorithm that eliminates The Herd Effect
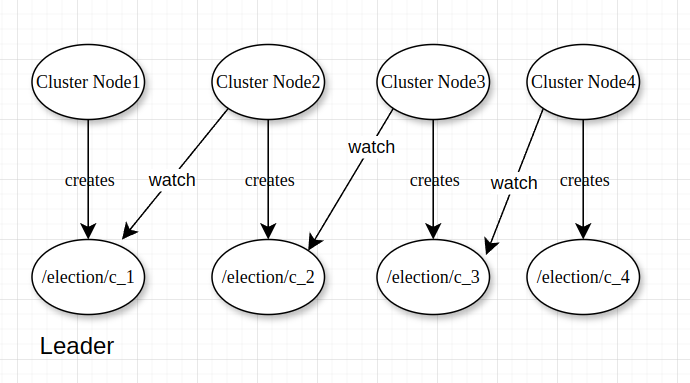
After the initial leader election, all the Nodes will not watch the leader’s znode. Instead, each Node is going to watch only the znode that comes right before it in the sequence of candidate znodes.
If the Leader dies, the only Node that gets notified is it’s immediate successor.
That Node will call getChildren() again to make sure that it owns the znode with the smallest sequence number. If that is the case, it knows that it is the new leader.
If a Node dies and it is not the Leader, the gap between the Node before it and the Node after it must be bridged. The Node after it in the sequence must start watching the znode of the Node before this in the sequence.
Internal references
Without fault tolerance: https://github.com/explorer436/programming-playground/blob/main/java-playground/zookeeper-examples/04watchers-and-triggers/src/main/java/distributed/systems/with/zookeeper/WatchersDemo.java
Fault Tolerance and Horizontal Scalability
These are very important properties
Fault Tolerance - The business can run 24X7 with no interruptions. We don’t have to worry that some hardware failures are going to bring the business down. Horizontal Scalability - We can dynamically grow our business on demand.