Kafka - Consumers and Consumer Groups
Kafka consumer
- A program you write to get data out of Kafka. Sometimes a consumer is also a producer, as it puts data elsewhere in Kafka.
- Consumers read data from a topic (identified by name) -
pull model.------------ Topic A - Partition 0 |-- |0|1|2|3|4|5|6|7|8|9|10|11|12| -> | Consumer 1 | ------------ ------------ Topic A - Partition 0 |-- |0|1|2|3|4|5|6|7|8|9|10|11|12| -> | | | | Consumer 2 | Topic A - Partition 0 |-- |0|1|2|3|4|5|6|7|8|9|10|11|12| -> | | ------------ - Consumers automatically know which broker to read from.
- In case of broker failures, consumers know how to recover.
- Data is read in order from low to high offset within each partition.
- There is no order guaranteed across partitions.
Push or Pull architecture?
Producers use the push model and consumers use the pull model.
Kafka is not going to dump all the messages that it has on the consumers. The consumers have to request Kafka for messages and Kafka will provide the messages to them. Consumers can customize/adjust the rate at which they consume messages from Kafka. e.g. The number of messages in a given duration, etc.
root@ba7f577efce3:/kafka/bin# ./kafka-console-consumer.sh
This tool helps to read data from Kafka topics and outputs it to standard output.
--max-messages <Integer: num_messages> The maximum number of messages to
consume before exiting. If not set,
consumption is continual.
Consumer groups
https://kafka.apache.org/documentation/#basic_ops_consumer_group
Lets assume that we have a scenario where the producer is writing messages to Kafka at a very high speed and the consumer takes a little bit of time to process the message that it is reading from Kafka.
e.g. Producer is writing 1000 messages per second. But the consumer application is able to process only one message per second. So, the number of consumer instances should be high.
If there is more than one instance of the consumer (performing the same functionality, like, payment process for an order event) in the consumer cluster, how do we control which consumer instance reads the message and processes it? We want only one instance of the consumer application to process each message from Kafka.
It is important to group all the consumer instances into a single consumer group.
What happens if we keep creating consumer instances without specifying a consumer group? The default behavior of Kafka is, it will assign a random value for consumer-group-id for every consumer. If we create 10 instances of a consumer application without grouping them, each of them will get a random consumer-group-id from Kafka. And because their consumer-group-ids are different, all of them will keep reading messages from Kafka (duplication of efforts).
kafka delivers to each consumer-group separately.
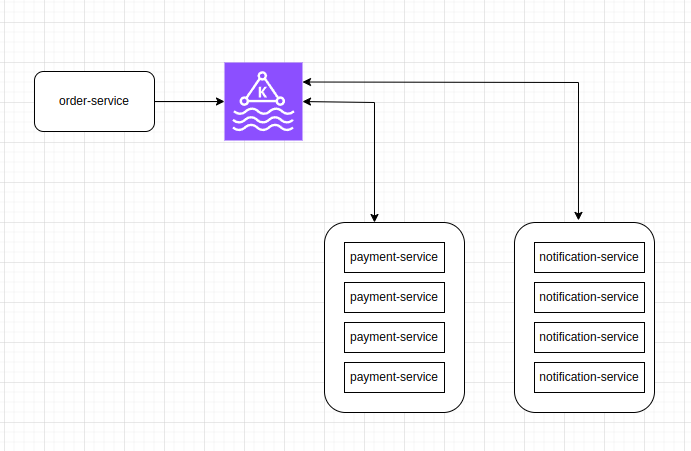
All the consumers in an application read data as a consumer group.
e.g.
- We can have a kafka topic with 5 partitions - Partition0, Partition1, Partition2, Partition3, Partition4
- And, a consumer group with three consumers - Consumer1, Consumer2, Consumer3.
- Each consumer within a group reads from exclusive partitions.
- Consumer1 reads from Partition0 and Partition1.
- Consumer2 reads from Partition2 and Partition3.
- Consumer3 reads from Partition4.
What if we have more consumers than partitions?
- If we have more consumers than partitions, some consumers will be
inactiveor idle. - We cannot assign one Partition to two different consumers (in a consumer group) - if we do, the ordering of the messages will not work.
- e.g. Scenario1:
- Topic A - Partition0 - Consumer0 is reading from this partition.
- Topic A - Partition1 - Consumer1 is reading from this partition.
- Topic A - Partition2 - Consumer2 is reading from this partition.
- e.g. Scenario 2:
- Topic A - Partition0 - Consumer0 is reading from this partition.
- Topic A - Partition1 - Consumer1 is reading from this partition.
- Topic A - Partition2 - Consumer2 is reading from this partition.
- And there is an extra consumer called Consumer4
- In Scenario 2, Consumer4 will be inactive.
The maximum number of consumers we would need in a consumer group is equal to the number of partitions on that topic.
Multiple consumers on one topic
-
In Apache Kafka,
it is acceptable to have multiple consumer groups on the same topic. -
e.g. Topic A - Partition0, Partition1, Partition2
Consumer group and application Possible scenarios scenario 1: consumer-group-application-1 -> Consumer1 reads from Partition0 and Partition1 and Consumer2 reads from Partition2. scenario 2: consumer-group-application-2 -> Consumer1 reads from Partition0. Consumer2 reads from Partition1. Consumer3 reads from Partition2. scenario 3: consumer-group-application-3 -> Consumer1 reads from Partition0, Partition1 and Partition2. -
As we can see, we can have multiple consumer groups reading from the same topic. Each partition will have multiple readers. But
within a consumer group, only one consumer is assigned to one partition in a topic.Why would we have multiple consumer groups?
- Going back to the truck example, we have one consumer-group that needs to create a “location dashboard”; and another consumer-group that need to set up “notification services” based on this data;
- To create distinct consumer groups, use the consumer property
group.id - In these groups, you can define
consumer offsets Kafka stores the offsets at which a consumer group has been reading.- The offsets committed are in a Kafka topic named
__consumer_offsets(two underscores at the beginning because it is an internal kafka topic). - When a consumer in a group has processed data received from kafka, it should be periodically committing the offsets (the kafka broker will write to
__consumer_offsets, not the group itself). - If a consumer dies, it will be able to read back from where it left off - thanks to the committed consumer offsets.
Delivery semantics for consumers
By default, Java Consumers will automatically commit offsets (At least once).- If you choose to commit manually, there are 3 delivery semantics.
At least once(usually preferred)- Offsets are committed after the message is processed
- If the processing goes wrong, the message will be read again
- This can result in duplicate processing of messages. Make sure your processing is idempotent (i.e. processing the messages again will not impact your systems)
At most once- Offsets are committed as soon as messages are received.
- If the processing goes wrong, some messageswill be lost (they will not be read again)
Exactly once- For kafka => kafka workflows: use the Transactional API (easy with Kafka Streams API)
- For kafka => External System workflows: use and idempotent consumer
Consumer Configuration
Consumer Deserializer
- Deserializer indicates how to
transform bytes into objects/data. - In a way, this does
the opposite function of what the producer serializer does. - The serialization/deserialization type (datatype) must not change during a topic lifecycle (If necessary, create a new topic instead).
- e.g. changing the key type from Integer to String is not allowed for a topic (because the consumers will be looking for that specific datatype)
Reset offset
When would we have to do this?
We want to start consuming messages --from-beginning because, some of the consumers in our consumer-group messed up, or the code has a bug or some other reason like that.
Possible values in kafka java library.
public enum OffsetResetStrategy {
LATEST, EARLIEST, NONE;
@Override
public String toString() {
return super.toString().toLowerCase(Locale.ROOT);
}
}
In consumer config, this would look like this:
Look at ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OffsetResetStrategy.EARLIEST.toString()
Map<String, Object> consumerConfig = Map.<String, Object>of(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class,
ConsumerConfig.GROUP_ID_CONFIG, "demo-group-123",
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OffsetResetStrategy.EARLIEST.toString(),
ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "1"
);
Session Timeout Config
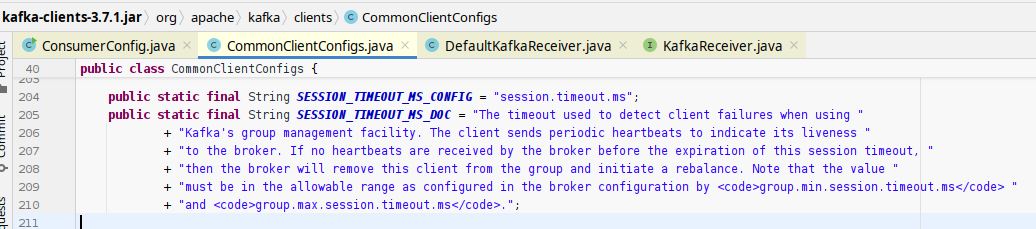
When new consumers join a consumer-group (especially, without a group.instance.id) and ask Kafka to deliver messages, if Kafka already delivered messages from partitions in that topic to other consumers before, Kafka will not deliver messages to the new consumers immediately. Kafka will try to ping those previous consumers and wait to hear from them. If Kafka doesn’t hear from those previous consumers, it will deliver messages to the new consumers.
So, for new consumers, there will be a delay of 45 seconds before they receive any messages from Kafka - if Kafka worked with other consumers before.
ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "1"
If consumers have a group id assigned, and if they restart, kafka will not wait for 45 seconds and it will deliver messages immediately, because it will recognize the consumer by that group.instance.id.
Acknowledging message
If the consumer doesn’t acknowledge, because we are setting ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OffsetResetStrategy.EARLIEST.toString(), if this consumer restarts, Kafka will deliver all the messages starting from the beginning. But we don’t want that to happen.
This is why the consumer needs to acknowledge each offset after processing it.
KafkaReceiver.create(options)
.receive()
.doOnNext(r -> log.info("key: {}, value: {}", r.key(), r.value()))
// acknowledge after processing the message. Not before.
.doOnNext(r -> r.receiverOffset().acknowledge())
.subscribe();
What if the consumer doesn’t acknowledge some offsets?
|1|2|3|4|5|6|7|8
If the consumer doesn’t acknowledge offsets 2 and 3 but acknowledges offset 4 and if the consumer restarts, what is the next message that will be delivered by kafka to this consumer?
Kafka will start from offset 5.
auto.commit.interval.ms
auto.commit.interval.ms = 5000
/**
* <code>auto.commit.interval.ms</code>
*/
public static final String AUTO_COMMIT_INTERVAL_MS_CONFIG = "auto.commit.interval.ms";
private static final String AUTO_COMMIT_INTERVAL_MS_DOC = "The frequency in milliseconds that the consumer offsets are auto-committed to Kafka if <code>enable.auto.commit</code> is set to <code>true</code>.";
All the acknowledgements from the consumer are not committed to the Kafka broker in real-time. They are collected for a certain amount of time and then committed to the broker.
For this reason, sometimes, even if the consumer acknowledges an offset, if that acknowledgement is not committed to the broker, and if the consumer restarts in the meantime, there is a possibility that the consumer will receive a message from Kafka that the consumer already processed before.
enable.auto.commit
enable.auto.commit = false
/**
* <code>enable.auto.commit</code>
*/
public static final String ENABLE_AUTO_COMMIT_CONFIG = "enable.auto.commit";
private static final String ENABLE_AUTO_COMMIT_DOC = "If true the consumer's offset will be periodically committed in the background.";
partition.assignment.strategy
https://kafka.apache.org/24/javadoc/org/apache/kafka/clients/consumer/ConsumerPartitionAssignor.html
What is the default? RangeAssignor. This works by using the sort mechanism. When a new Consumer joins the ConsumerGroup, the partition with the highest number will be assigned to it.
public static final String PARTITION_ASSIGNMENT_STRATEGY_CONFIG = "partition.assignment.strategy";
private static final String PARTITION_ASSIGNMENT_STRATEGY_DOC = "A list of class names or class types, " +
"ordered by preference, of supported partition assignment strategies that the client will use to distribute " +
"partition ownership amongst consumer instances when group management is used. Available options are:" +
"<ul>" +
"<li><code>org.apache.kafka.clients.consumer.RangeAssignor</code>: Assigns partitions on a per-topic basis.</li>" +
"<li><code>org.apache.kafka.clients.consumer.RoundRobinAssignor</code>: Assigns partitions to consumers in a round-robin fashion.</li>" +
"<li><code>org.apache.kafka.clients.consumer.StickyAssignor</code>: Guarantees an assignment that is " +
"maximally balanced while preserving as many existing partition assignments as possible.</li>" +
"<li><code>org.apache.kafka.clients.consumer.CooperativeStickyAssignor</code>: Follows the same StickyAssignor " +
"logic, but allows for cooperative rebalancing.</li>" +
"</ul>" +
"<p>The default assignor is [RangeAssignor, CooperativeStickyAssignor], which will use the RangeAssignor by default, " +
"but allows upgrading to the CooperativeStickyAssignor with just a single rolling bounce that removes the RangeAssignor from the list.</p>" +
"<p>Implementing the <code>org.apache.kafka.clients.consumer.ConsumerPartitionAssignor</code> " +
"interface allows you to plug in a custom assignment strategy.</p>";
If we use this,
ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, CooperativeStickyAssignor.class.getName()
When a new Consumer joins a ConsumerGroup, Kafka will not reassign partitions from Consumers that are handling only one partition. Instead, it will look at Consumers handling more than one partition, then take one partition from that Consumer and assign it to the new Consumer.
auto.offset.reset
https://docs.confluent.io/platform/current/clients/consumer.html#offset-management
Possible values: latest, earliest
Default value is latest
After a consumer instance starts and joins a consumer-group, instead of reading messages from that point of time, read the messages from the earliest committed offset.
17:07:02.465 [main] INFO o.a.k.c.consumer.ConsumerConfig - ConsumerConfig values:
allow.auto.create.topics = true
auto.commit.interval.ms = 5000
auto.include.jmx.reporter = true
auto.offset.reset = earliest